Implement your CI/CD process with Red Hat OpenShift Pipelines
OpenShift gives you several options to build and deploy applications and in previous articles I already explored a couple of them:
- OpenShift Template: a Template is a straightforward way to describe all the objects that are needed to actually deploy an application to OpenShift (typically, but not exclusively, DeploymentConfig, Service, Route and maybe BuildConfig) and have full control over their configuration; you can read Implement an OpenShift deployment strategy using Templates for more details;
- Jenkins pipeline: yes you can use the good old Jenkins to implement your CI/CD process on OpenShift; I wrote an article on this as well, have a look at the link Using Jenkins pipelines to implement CI/CD on Red Hat OpenShift for details.
In this article I will explore a third option, using OpenShift Pipelines (based on Tekton technology). The scenario I am going to describe is quite easy:
- Source code for the application is in a private GitHub repository;
- Container image that is created during the build process is pushed to a private Quay (https://quay.io/) image registry (I personally use Quay but the process I am going to describe can easily be adapted to registries like Docker Hub or others);
- An OpenShift cluster is up and running somewhere, ready to run the application;
- A Pipeline is defined within the OpenShift cluster to coordinate the tasks to clone the repository, build the image, push to the private registry, deploy to OpenShift and expose a Route.
Tekton and OpenShift Pipelines
As described in Tekton open source project website (https://tekton.dev/):
Tekton is a powerful and flexible open-source framework for creating CI/CD systems, allowing developers to build, test, and deploy across cloud providers and on-premise systems.
Red Hat OpenShift Pipelines is a cloud-native CI/CD solution fully based on Kubernetes resources that uses Tekton concepts and building blocks to automate deployments across multiple platforms by abstracting away the underlying implementation details. Tekton introduces a number of standard Custom Resource Definitions (CRDs) for defining CI/CD pipelines that are portable across Kubernetes distributions.
Refer to https://docs.openshift.com/container-platform/4.6/pipelines/understanding-openshift-pipelines.html for more information.
Install OpenShift Pipelines
Before even thinking of using OpenShift Pipelines framework, you obviously need to install it in your cluster; Red Hat provides an Operator to simplify the installation process.
Go to OpenShift web console, select Operators → Operators Hub from the navigation menu on the left and then search for the OpenShift Pipelines Operator.
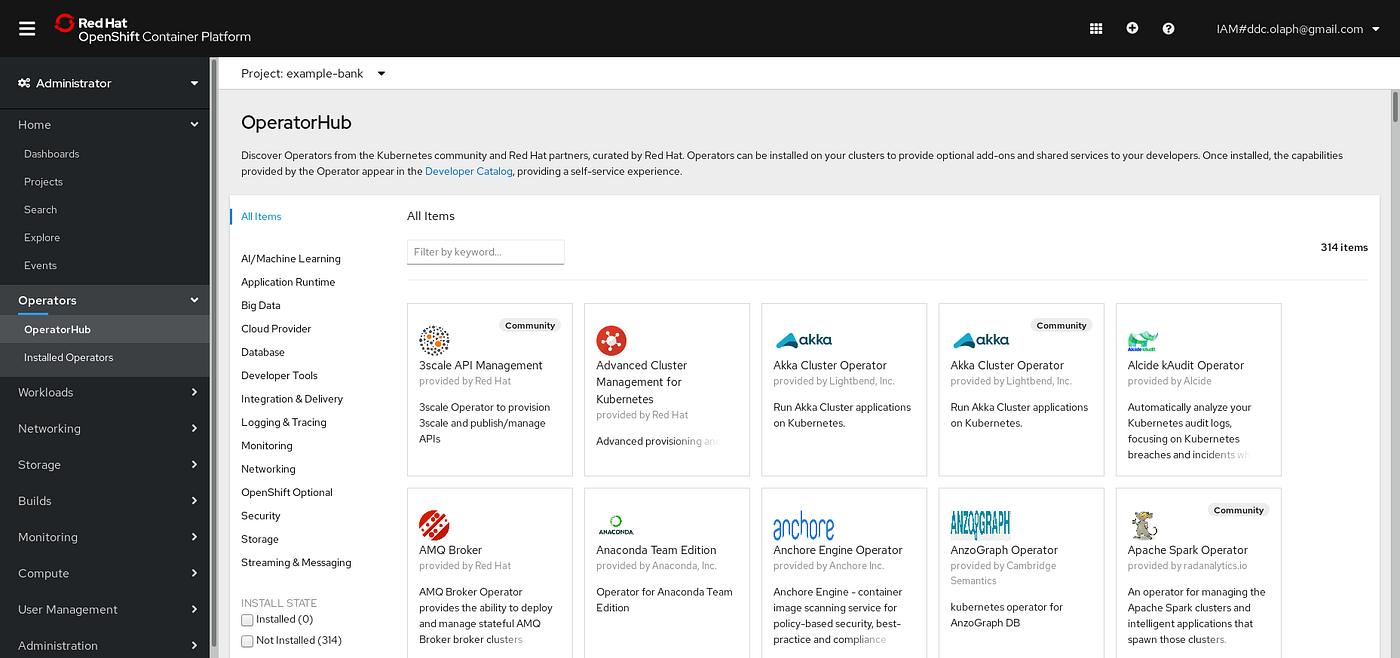
Click on the tile and then the subsequent Install button, as the following:

Keep the default settings on the Create Operator Subscription page and click Subscribe.
With these few easy steps we have installed OpenShift Pipelines and we are now ready to use this Tekton-based framework to create a pipeline to build and deploy applications, but be patient: we still need a couple of preliminary steps to lay down our foundation, so let’s start.
Configure Service Account
Before running OpenShift pipelines we need to make sure the right permissions are in place, and the way to do it is by configuring a Service Account appropriately. When you install OpenShift Pipelines Operator, the pipeline Service Account is created to actually run Tekton Tasks and Pipelines, so we will grant the right permissions to it.
Remember that GitHub repository is private so OpenShift pipelines will need credentials to access GitHub, clone the repository and access the source code to build the application. For this reason let us start with creating a Secret where we will store GitHub credentials.
## Remember to first authenticate to OpenShift with oc login
## Set OpenShift project where your application will be deployed
## Remember <YOUR_OPENSHIFT_PROJECT> project must pre-exist
oc project <YOUR_OPENSHIFT_PROJECT>
oc create secret generic <YOUR_GITHUB_SECRET_NAME> \
--from-literal=username=<YOUR_GITHUB_USERNAME> \
--from-literal=password=<YOUR_GITHUB_PERSONAL_ACCESS_TOKEN> \
--type=kubernetes.io/basic-auth
## Annotate the Secret appropriately
oc annotate secret <YOUR_GITHUB_SECRET_NAME> "tekton.dev/git-0=https://github.com"Remember that Quay image registry is also private so OpenShift pipelines will need credentials to push images to Quay and for this reason we will create another Secret where we will store Quay credentials.
oc create secret docker-registry <YOUR_REGISTRY_SECRET_NAME> \
--docker-server=<YOUR_REGISTRY_URL> \
--docker-username=<YOUR_REGISTRY_USERNAME> \
--docker-password=<YOUR_REGISTRY_PASSWORD>
## Annotate the Secret appropriately
oc annotate secret <YOUR_REGISTRY_SECRET_NAME> "tekton.dev/docker-0=quay.io"Once the Secrets have been created, let us bring everything together, set the appropriate privileges and link the Secrets to pipeline Service Account with the following commands:
## Add a privileged Security Context Constraint to
## pipeline Service Account
oc adm policy add-scc-to-user privileged -z pipeline
## Add an edit Role to pipeline Service Account
oc adm policy add-role-to-user edit -z pipeline
### Link GitHub Secret to pipeline Service Account
oc secrets link pipeline <YOUR_GITHUB_SECRET_NAME>
### Link Image Registry Secret to pipeline Service Account
oc secrets link pipeline <YOUR_REGISTRY_SECRET_NAME>
### Link Image Registry Secret to default Service Account
oc secrets link default <YOUR_REGISTRY_SECRET_NAME> --for pullCreate a PersistentVolumeClaim
One final preparatory step is needed before we can actually run OpenShift pipelines.
Remember that in Tekton every Task runs in its own container, so to allow different Tasks to share content (e.g.: one Task fetches source code from a repository and another Task builds application from source code) we need to put Persistent Storage into the equation. How you manage Persistent Storage largely depends on the infrastructure your OpenShift cluster runs on; in my case I use IBM Cloud which has a convenient Block Storage service and the only thing I need is to define a PerstistentVolumeClaim like this pvc.yaml and IBM Cloud will provide an appropriate Block Storage volume for me.
Creating the PersistentVolumeClaim in OpenShift is as easy as this:
## Create a PersistentVolumeClaim
oc create -f pvc.yamlWARNING: ensure the PersistentVolumeClaim is bound before trying to run the pipeline.
Launch OpenShift Console, click on Storage → PersistentVolumeClaim menu on the left and ensure you see something like this:

Create an OpenShift Pipeline
Having done all the preparation we are now ready to create our pipeline. You can have a look at this example windfire-restaurants-backend-pipeline.yaml for a fully functional Pipeline that is general enough and easy to adapt to your case.
Create the pipeline by running this command:
## Create Tekton Pipeline
oc create -f windfire-restaurants-backend-pipeline.yamlLaunch OpenShift console and click on Pipelines → Pipelines menu on the left, then select the pipeline you just created and what you get with the above example, properly adapted to your case, is something like the following:

These are 4 straightforward Tekton Tasks, ran sequentially, that:
- Get source code from a GitHub repository;
- Build a container image from a Dockerfile and push to a container registry;
- Deploy the image to OpenShift;
- Expose the application with a Route for external access.
Let us dig a little bit into the anatomy of the pipeline; at the beginning of the spec section, there are 2 areas:
- workspace section, which defines a workspace that can be bound to a Persistent Storage once the pipeline will be run;
- params section, where all the parameters that can be accepted by the pipeline are defined, with their default values, if any.

The fetch-repository Task, that you can see in the Figure below, is responsible for cloning the source code repository; it has its own parameters, whose meaning should be quite clear and a workspaces section that binds the output to the workspace that has been defined before (see Figure x). To notice also, that the Task refers to the git-clone ClusterTask: ClusterTasks are cluster wide commonly useful tasks implemented for you and made available by Red Hat OpenShift, so that you can just reuse without reinventing the wheel yourself.

The build-image Task is responsible for building and pushing the image to the registry, based on the value of $(params.IMAGE) parameter; in my case this is quay.io/robipozzi/windfire-restaurants-node:1.0, so it will try to push to Quay private registry (and that is exactly the reason why I had to create the Secret). It is based on buildah ClusterTask, which builds the image based on a Dockerfile it expects to find in the root of the GitHub repository; notice the runAfter section that just tells the pipeline to run the task only after fetch-repository Task has completed.
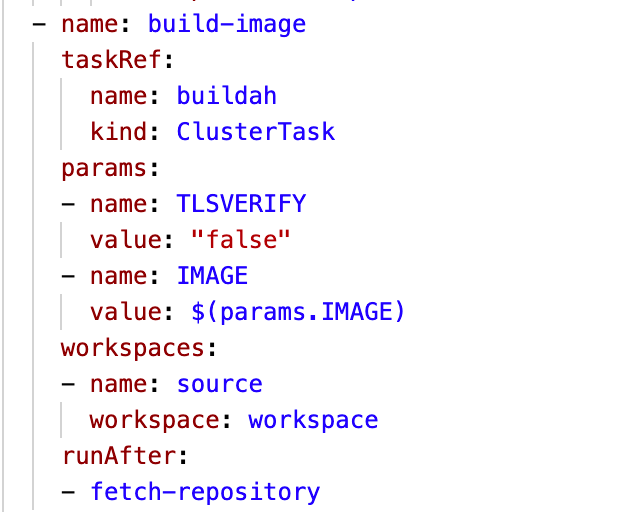
The deploy Task is responsible for deploying the image, built in the previous step, to OpenShift. Notice it is based on another ClusterTask, openshift-client, which allows to use oc command line within the pipeline, and in fact in my case the deployment is done by using a convenient oc new-app command.

Finally the expose-route Task is responsible for exposing an OpenShift Route in order for the application to be accessible; no further explanations should be needed.

Run the Pipeline
Now that you have designed and implemented an OpenShift Pipeline you probably would like to use it, and you can do it in a couple of way:
- Run a pipeline via command line with Tekton Pipelines CLI;
- Run a pipeline using OpenShift GUI.
I will show how to use both in a second; technically you can also configure GitHub Webhooks in order to trigger the pipeline execution at every push occurring in GitHub repository but I will leave this to another article.
Run the Pipeline with Tekton Pipelines CLI
To run a pipeline from command line, you first need to install Tekton Pipelines CLI (tkn), have a look at the link https://github.com/tektoncd/cli for instructions.
Once you have installed tkn you can just run every pipeline you have with a command like the following:
tkn pipeline start <YOUR_PIPELINE> -s pipeline \
-w name=workspace,claimName=<YOUR_PVC_NAME> \
-p APP_NAME=<YOUR_APPLICATION_NAME> \
-p GIT_REPO=<YOUR_GITHUB_REPO_URL> \
-p IMAGE=<YOUR_CONTAINER_IMAGE_NAME> Notice that -w name=workspace,claimName=<YOUR_PVC_NAME> statement: here is where you actually bind the workspace (that we have seen throughout the pipeline definition before) to a PersistentVolumeClaim, making workspace persistent and allowing Tasks to share content.
All those -p statements are simply the way to pass actual values to the pipeline parameters, you will obviously need to adapt to your case.
Run the Pipeline using OpenShift GUI
Launch OpenShift console and click on Pipelines → Pipelines menu, then select the pipeline you just created and you should end up with something similar to this:
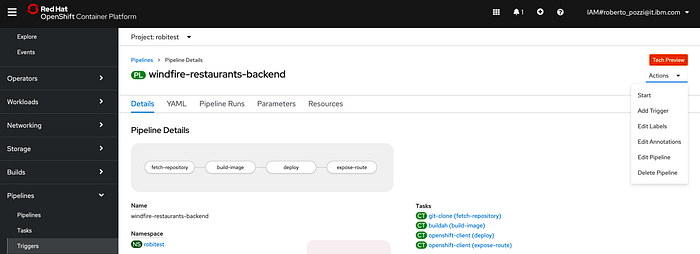
Open that Actions drop down menu in the right corner, click Start to run the pipeline and a form like the following will pop up:
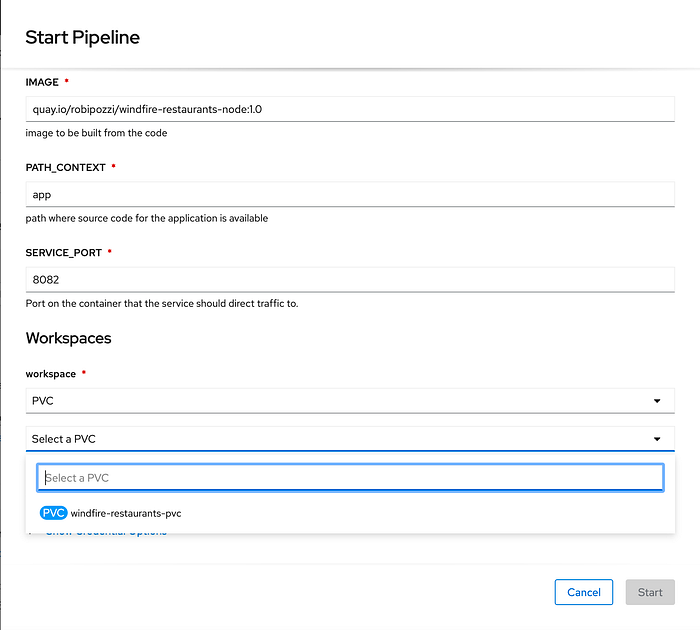
Depending on the parameters you defined for your pipeline you will obviously be presented different input fields; what I want to draw your attention on is that Workspaces section: there you have the chance to select the PersistentVolumeClaim that will provide persistent storage to your pipeline, well actually it is not simply a chance but you must do it or your pipeline will not work.
This is it and I hope I gave you a good overview of what to do to use OpenShift Pipelines framework to build your own pipelines, good work!
What to read next
This article is part of a series of articles exploring the options you have to build and deploy applications to OpenShift, you can read the other related articles at the following links: